
Healthcare Data Platforms collect and store patient healthcare related information from various sources to help organizations understand healthcare history. It also allows health systems to create holistic views of patients, advance treatment methods, create personalize treatments, improve communication between doctors and patients, and enhance health outcomes.
When working on a daily base, with our health and life-science customers, who are starting or accelerating on their data platform journey, it became clear that a healthcare data platform journey could help many in understanding the foundations and what is needed to enable such a platform.
Step wised approach
In this post I will take you through 6 basic steps that will give some foundational, but also crucial information on what is essential to build your healthcare data platform.
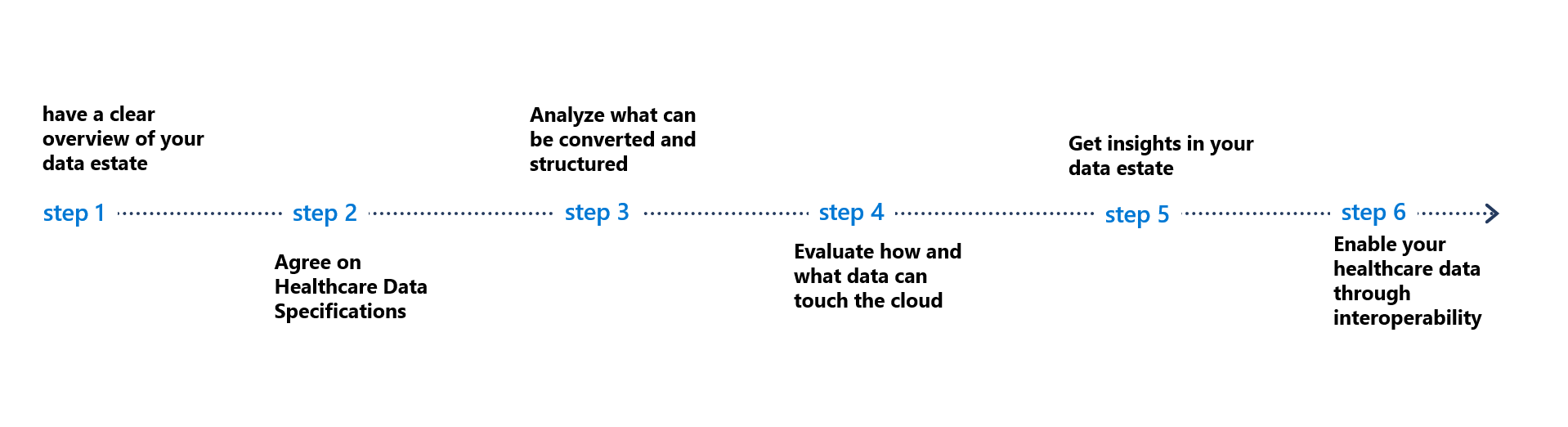
1. Have a clear overview of your data estate
Healthcare data comes from various disparate data sources, it has many formats and sizes, and they come with different security and compliance boundaries. This means that the first step is having a clear overview of your current data estate.
At a high level we can divide healthcare data into 2 main categories
Structured Data
- HL7 (v2/v3/FHIR)
- C-CDA
- OMOP
- DICOM (Headers)
- BAM – CRF
- Claims Data
- IoMT
- ….
Unstructured Data
- Clinical Notes
- Referral Letters
- Medical Images
- …
2. Agree on healthcare data specifications
When ingesting data from different sources it is important that you select one or more healthcare specifications. Within Europe there are 3 well-known healthcare specifications, and each of them have their own role to play.
FHIR is a standard that provides healthcare data formats based on Resources, it contains an API specification and has a very active community. The same goes with openEHR, which is build for long-term clinical storage with their Archetypes, where they focus on the separation of data from the application layer. OMOP is mainly used for Real World Evidence (RWE) data and (medication) research.

It could be perfectly possible that, at some point, you will use these 3 standards in your data platform.
As healthcare specifications can and will be used together in a platform, it is essential you agree on healthcare terminology, classification and coding standards, such as SNOMED, LOINC, ICD10, … Most of these can then also be linked to together through vocabularies such as Unified Medical Language System (UMLS) (nih.gov)
3. Analyze what can be converted and structured
The next step is to start analyzing what and how you will convert your data-sources to which standard. If you are interested in Real World Evidence use cases or medication studies, then OMOP could be your standard. If you want to capture clinical patient information then FHIR or openEHR is what you are looking for. There are a number of technical differences between them, such as openEHR is based on Archetypes versus Resources in FHIR, there is a difference in FHIR search and openEHR AQL, etc.
There has been a lot of FHIR investments from the Industry due to the U.S. regulations. Companies such as Microsoft already created several managed and open-source FHIR tooling’s to accelerate data transformation into FHIR and provided ways to utilize FHIR in their cloud platform.
Microsoft already has their own open-source FHIR server and a Managed Healthcare Data Service , they also created many solutions to accelerate data conversion and ingestion into FHIR. The strategy behind this, is to make it as easy as possible to start with your data platform journey.
In the image below you see how data such as IoMT, legacy data (HL7v2/C-CDA/JSON), unstructured data and medical images (DICOM headers) can all be transformed and ingested into a single FHIR repository.
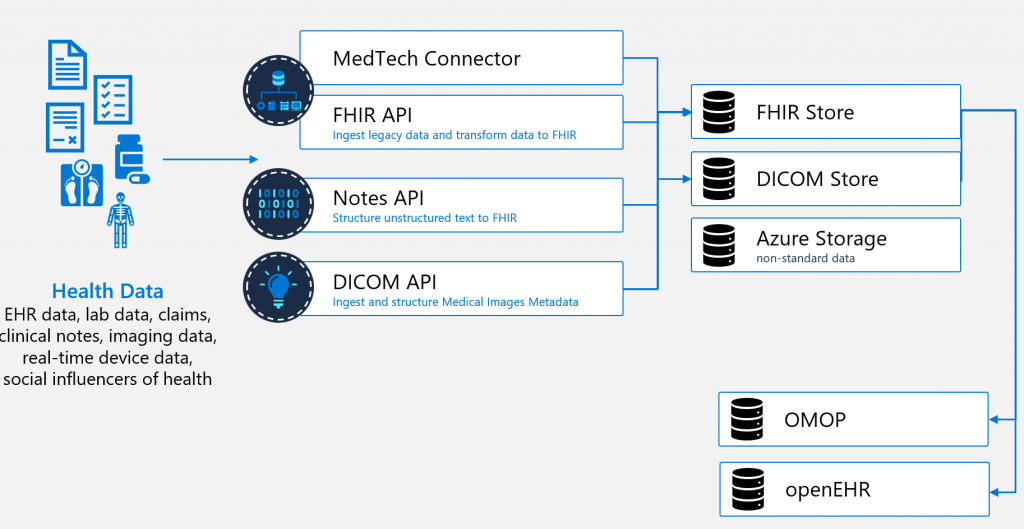
When already having a pipeline that can ingest and transform different data-sources, and convert that to one standard such as FHIR, it would then be very interesting to see how we can enable FHIR to OMOP or FHIR to openEHR as you don’t want to do the initial transformation and codification multiple times.
You can find another representation of this on the image below. Where data ingestion and transformation is done through FHIR but where there is an integration with the openEHR Clinical Data Repository.
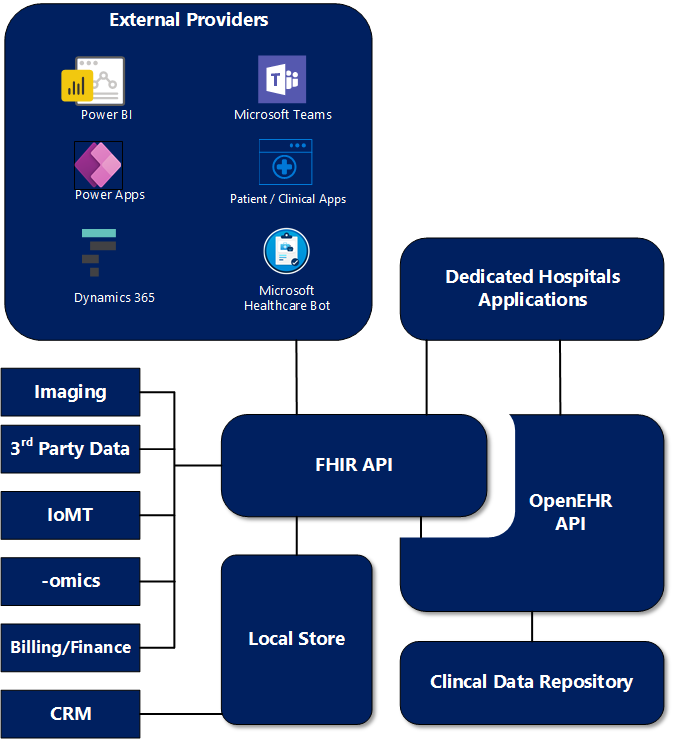
Technically you could also ingest data directly to openEHR, but due to the fact that the Industry has already tackled and developed these functionalities on FHIR, it would take years of development and investment to make this happen on openEHR.
4. Evaluate how and what data can touch the cloud
When working with healthcare data in Europe, we need to be aware of compliance and security regulations such as GDPR or Schrems 2. In some countries, not all data can touch the cloud without making sure its anonymized or pseudonymized. There are several ways on how you can tackle this.
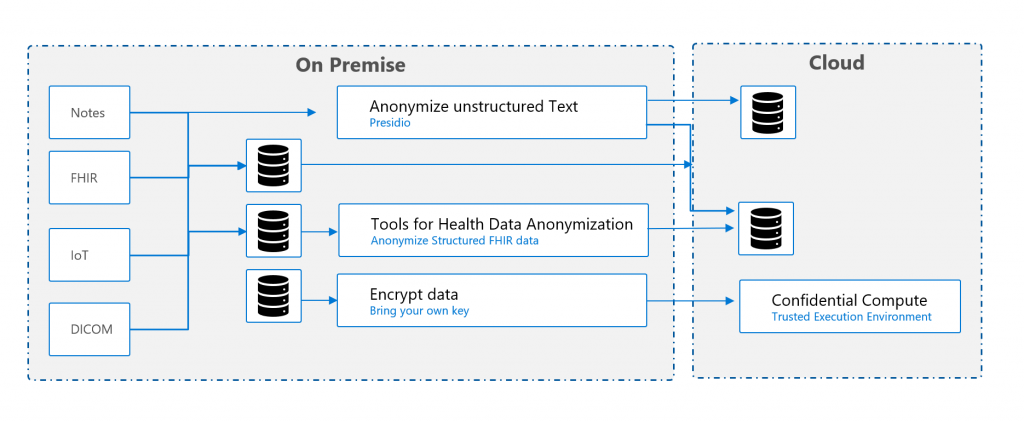
Below you can find a couple of examples which has been validated or rolled-out by other organizations. The examples are mainly on the FHIR spec, but are not limited to this.
Export de-identified data before sending it to the cloud
Setup a FHIR server on-premise, where data from different sources are transformed and converted into a single FHIR server. When sharing or using the data in a public cloud, you can then export de-identified data to any FHIR compliant server.
Split up FHIR resources
Have an on-premise FHIR service that only contains the patient resource and have a cloud FHIR service that contains all other relevant resources such as observations, conditions, encounters, .. All the resources are linked to a certain (hashed) subject-id, which is an random generated identifier. You will need to put a proxy in front of your services, to enable orchestration between the different FHIR servers. The proxy can also be used to remove or mask data, to make sure data is not being exposed.
Confidential Compute
All persisted on-premises data can be encrypted and send to the cloud, where with the support of Confidential Compute you protect data in use, by performing computation in a hardware-based Trusted Execution Environment. These secure and isolated environments prevent unauthorized access or modification of applications and data while in use.
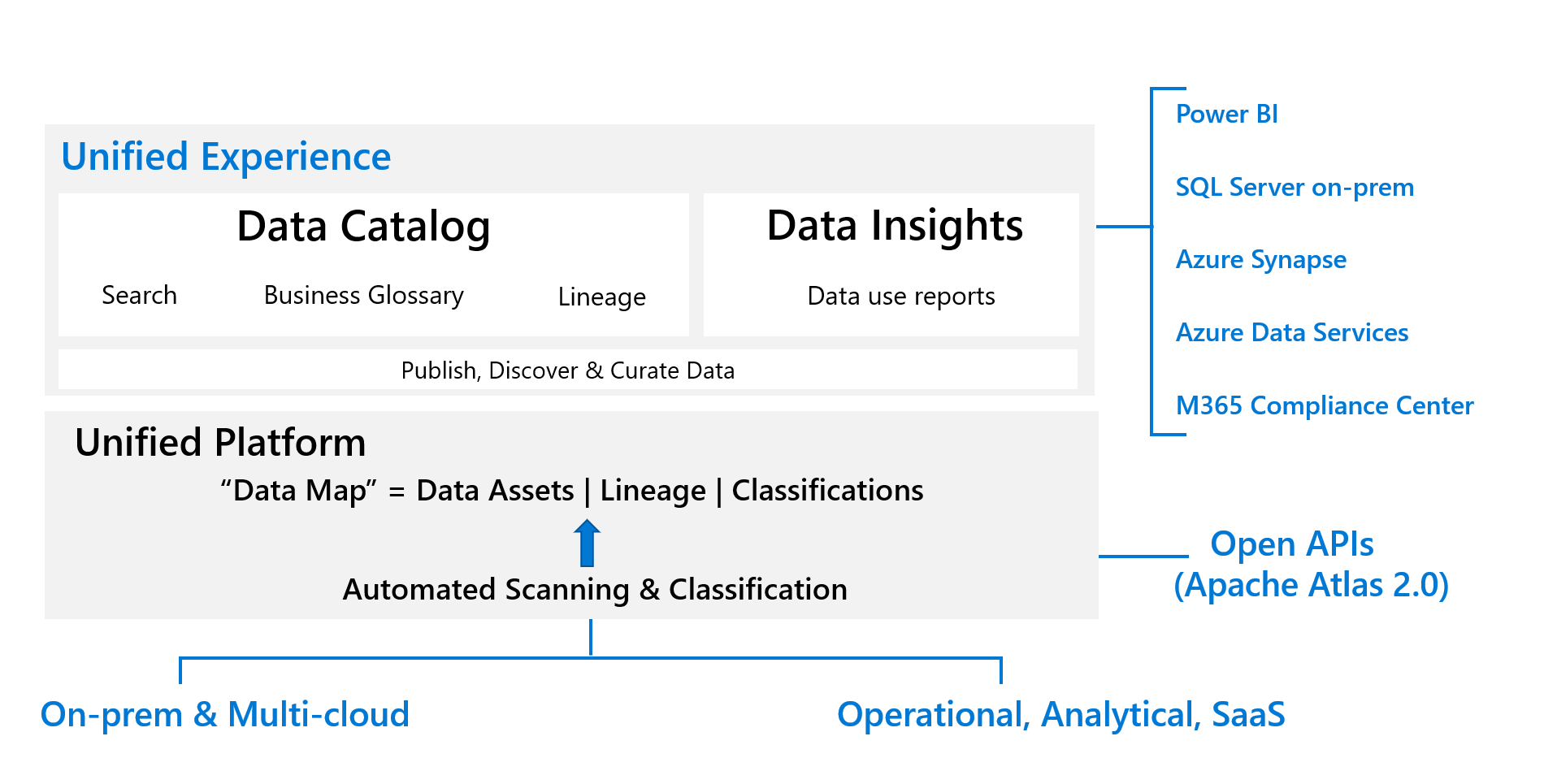
5. Get insights in your data estate
Another step is to get the needed insights and lineage in your data estate. Where is it coming from, how is it transformed, what coding specifications are we using in the organization , … With tools such as Azure Purview you can create your own Healthcare glossary on what coding specifications you are going to use, understand where data lineage and get the needed insights in your data estate
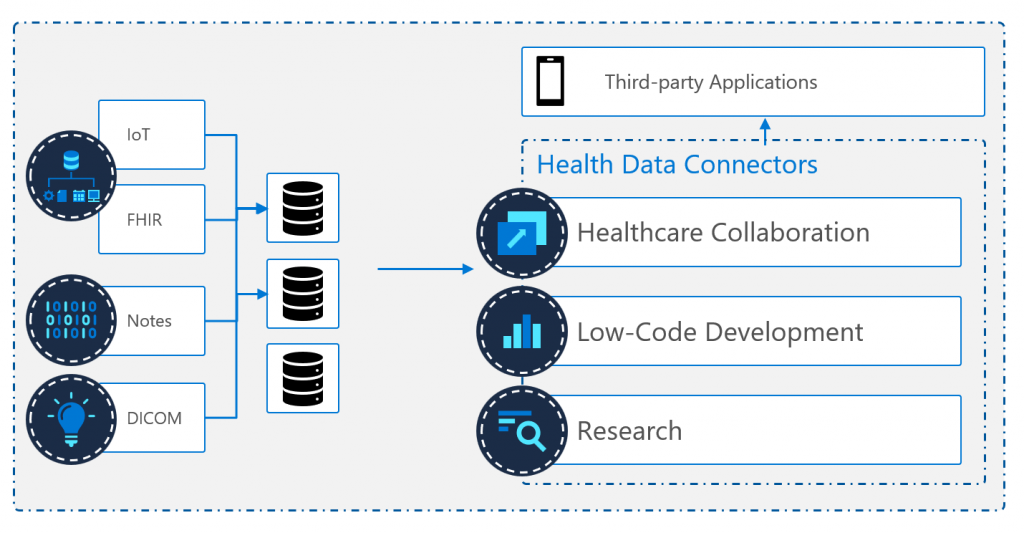
6. Enable your healthcare data through interoperability
When your data has been transformed, structured, and persisted, then you can start enabling your data with many different scenarios. Such as providing remote care to patients at home via IoMT, improving population health through A.I. or research, or improve healthcare diagnoses and insights through data, …
This all can be done in many ways, such as by using SMART on FHIR, or through one of the many FHIR enabled products and services in the Microsoft Eco-system. In the Power Platform Microsoft has created FHIRBase and FHIRClinical connectors for Power Apps or Power Automate. There is A PowerQuery connector for PowerBI. Or if you want to have a telemedicine platform, Microsoft has created a Dynamics 365 Bi-Directional FHIR sync agent in the Microsoft Cloud for Healthcare. For research there is also an FHIR to Synapse connector, which can export FHIR data to parquet format for research. And many other services such as the Microsoft Healthcare Bot, who are all enabled on the FHIR specification.
Personally, I believe that in the near future, data platforms will play a bigger role in healthcare and that standards such as FHIR, openEHR and OMOP will play a crucial role to make this happen.
Bert